
Demystifying Compliance with ABET Criterion 4
In the early 1990s ABET, the accreditation agency for engineering and technology programs, initiated a process to move away from inflexible criteria focused on what is taught and which courses are taken to criteria focused on what is learned. The Engineering Criteria 2000 (EC2000) initiative embraced an outcomes and evidence-based approach to both empower program innovation and drive program improvement through the assessment of student learning. This change motivated programs to reform teaching methods from lectures to instructional models that encouraged student learning and engagement through projects and assignments that illustrate learning in the context of application rather than focusing on isolated technical concepts and principles [1].Though the intent was to lessen the strict and prescriptive nature of accreditation, it may be argued that EC2000 clouded programs’ vision and resource-allocation with multiple competing priorities[2]. In addition, the lack of specific guidance and interpretation needed in how to demonstrate compliance with the ABET criteria leads many programs to view ABET accreditation as a mysterious process that requires luck and skill to master. In particular, Criterion 4 is the most cited shortcoming due to a lack of compliance with one or more steps of the required continuous improvement process: assessment, evaluation, and systematically using the results as feedback into the process.
In an attempt to make the process more transparent, ABET publicly released internal program evaluator training materials via the ABET website. In addition, ABET offers a wide variety of workshops and an annual symposium to help programs understand the nuances of the criteria and allow for interactions with ABET program evaluators and staff. Still, the lack of specific guidance and interpretation needed in how to demonstrate compliance with the criteria compounded with personal interpretation bias demonstrated by some program evaluators, were and remain a sore point for many programs [2].
Over the years, the topic of assessment and maintaining consistency between assessment workshop content and program evaluator training has risen multiple times during meetings of the Accreditation Council Training Committee (ACTC). The ACTC, which includes representation of all four Accreditation Commissions (Applied & Natural Sciences, Computing, Engineering, and Engineering Technology), is a subcommittee of the Accreditation Council of the ABET Board of Directors, responsible for the preparation and delivery of training for both program evaluators and team chairs. Its mission is to improve processes and promote uniformity across the Accreditation Commissions.
In 2019, ACTC formed a small ad hoc subcommittee with representatives possessing both accreditation and assessment expertise to develop a document addressing various misconceptions regarding Criterion 4 – misconceptions on the part of both the program and program evaluators. The resulting document was vetted through multiple iterations with feedback from the ACTC and all executive committee members of all four commissions. Based on the strongly positive response received, the document was forwarded to the Accreditation Council, which approved the document at its September 2020 meeting. This short document is provided as a PDF at the end of this article; the remainder of this paper provides additional detail regarding the guidance provided.
CRITERION 4
In its entirety, Criterion 4 states, “The program must regularly use appropriate, documented processes for assessing and evaluating the extent to which the student outcomes are being attained. The results of these evaluations must be systematically utilized as input for the program’s continuous improvement actions. Other available information may also be used to assist in the continuous improvement of the program.” As stated in the Criterion, assessment and evaluation are different components of the continuous improvement process. Because Criterion 4 is a harmonized criterion, all four ABET Commissions use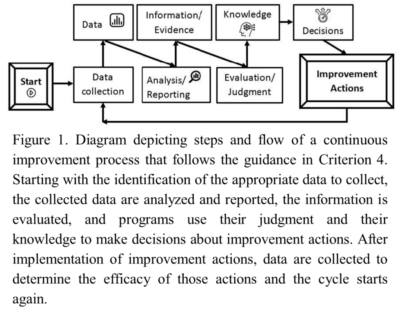 the following definitions for the terms. “Assessment” is one or more processes that identify, collect, and prepare data to evaluate the attainment of student outcomes. Once the data are in hand, “evaluation” is one or more processes for interpreting the data and evidence accumulated through assessment processes. Evaluation transforms the data into information and knowledge upon which decisions on improvement actions can be made. Fig. 1 depicts this process.
the following definitions for the terms. “Assessment” is one or more processes that identify, collect, and prepare data to evaluate the attainment of student outcomes. Once the data are in hand, “evaluation” is one or more processes for interpreting the data and evidence accumulated through assessment processes. Evaluation transforms the data into information and knowledge upon which decisions on improvement actions can be made. Fig. 1 depicts this process.
As assessment, evaluation, and improvement actions are separate processes, it is possible for a program to be compliant with regards to one of the processes but not the others. For example, a program may gather data on student learning and evaluate the data, but have only an ad hoc, non-systematic process for using the data in decision-making. Alternatively, the data for some of the outcomes may be missing altogether, even though an assessment and evaluation process is in place for the data that do exist.
ASSESSMENT
Assessment is at the core of Criterion 4, and several aspects of and questions about the assessment process are described in the following paragraphs – how to assess, where to assess, how much to assess, when to assess, measures to use, and so forth. Clearly, the design of an assessment process will depend on the context and circumstances of the program – its size, number of faculty, financial resources, and nature of the program. ABET encourages programs to devise an assessment process appropriate to a program’s unique context. In addition, ABET training materials and webinars help familiarize faculty with various assessment methods that can be used to measure attainment of outcomes and create a community in which faculty view assessment as a means to improve student learning rather than simply comply with criteria. Aspects of assessment processes that are often misunderstood are discussed below.
Course grades. It is sometimes claimed that an overall course grade – the summative result of a student’s performance following the completion of a term – can be used in assessment as evidence of student learning. For example, an instructor may assert that if a student earns a “C” or better in their course, then the student has successfully attained all ABET outcomes “covered” in that course. However, unless the instructor is using specification grading that requires students to demonstrate satisfactory attainment of all ABET outcomes covered in the class in order to obtain a “C” or better, then the course grade represents student performance in a variety of skills or knowledge areas and is not indicative of outcome attainment [3]. Additionally, a student with a “C” average could be strong in one outcome area and weak in another.
Evidence for student attainment of an outcome is much more direct if the instructor narrows the scope of the measure by selecting a specific assignment or exam within a course for the assessment of a particular outcome. As an example, to demonstrate students’ abilities to make informed ethical judgments, a program might ask a student to analyze a case study. The score on this focused assignment could provide a measure of degree of attainment of the student outcome. Furthermore, typical assignments or exams often require a student to demonstrate multiple outcomes. In such cases, the student performance can be assessed separately for each of those multiple outcomes. For example, the questions on an exam can be grouped into sections, which each section targeting a specific outcome. The scores attained by the class for a particular exam section can thence be used as data in support of that outcome.
Direct versus indirect assessment. A shortcoming often identified in the early EC2000 days was that programs relied too heavily, even entirely, on indirect rather than direct measurement of student learning. While this has been less of an issue in recent years, programs still need to recognize the difference between the two.
Direct assessment refers to direct observation of student performance against a measurable outcome; the assessment is done on examples of student work or performance [4]. Some examples of direct assessment methods include course-embedded assessment such as projects, homework, quizzes, exams, performance appraisals, and oral exams [4] in which the assessment is focused on a single outcome at a time. Since Criterion 4 refers to determining the “extent to which” outcomes are attained, it follows that measures, or assessment tools, are needed to provide direct evidence that allows the program to determine the extent of attainment based on observed student performance. Some research-based practices that have been shown to be successful in the assessment process include capstone reports scored with rubrics aligned with performance indicators to measure project management communication or leadership [6, 7, 8] and peer assessment tools available as part of CATME [5], a web tool that combines self/peer ratings to provide individual, team, and/or class feedback. These tools have proven to be both a reliable and valid instrument for measuring certain learning outcomes related to teamwork, communication, and project management.
Indirect assessment refers to anecdotal evidence or self-reported ability [9]. Examples of indirect assessment measures include student surveys, focus groups, and interviews [4]. Having a student perspective expressed via qualitative methods is a valid assessment that could yield valuable data and insights for aspects of student outcomes. This approach becomes particularly powerful when an outcome depends on student opinions, attitudes, and values (e.g., inclusion and team collaboration) – what is known as the affective domain [10]. However, in most cases, assessment based only on student perception is not compelling. Ethics is a common area in which assessment instruments are designed to probe students about their perceived ability to apply codes of ethics in their discipline [11] which can complement student examples of work of ethical applications.
Performance indicators. For each of the commissions, the student outcomes are worded such that they are broad statements of needed knowledge, skills, or attributes that an engineer, technologist, or computing professional should demonstrate upon graduation. For example, in the Engineering Accreditation Commission, Student Outcome 1 states that students must demonstrate “an ability to identify, formulate, and solve complex engineering problems by applying principles of engineering, science, and mathematics” (ABET Criteria 2021-2022) [12]. Since this statement is written as a complex sentence with multiple connected phrases, one must show attainment of this outcome by demonstrating an ability to (1) identify complex engineering problems by applying principles of engineering, science, and mathematics, (2) formulate complex engineering problems by applying principles of engineering, science, and mathematics, and (3) solve complex engineering problems by applying principles of engineering, science, and mathematics. This type of practice of separating phrases within an outcome is a preliminary step in generating performance indicators [13, 14]. Performance indicators are specific, measurable descriptors that give direct evidence of student learning related to the student outcome [15]. The use of performance indicators (PIs) is intended to clearly develop a common understanding, define the scope of the student outcome, and facilitate a more localized and targeted mapping of the assessment components to the outcomes [16]. When coupled with rubrics, results for attainment of performance indicators are a direct measure of student learning and may point toward areas needing improvement actions.
Where to assess. ABET defines outcomes as what students are able to do by the time of graduation. Programs are free to determine the number and level of courses in which assessment is performed to determine the extent to which outcomes are attained. ABET’s definition of student outcomes allows assessment to be concentrated toward the end of the curriculum [17]; however, programs should use caution if choosing to assess everything in just one, culminating course. Given the evaluation of assessment data and judgment applied by faculty, programs should be able to identify where in the curriculum improvements should be made, if an area for improvement is identified. The area for improvement may well be in courses other than those in which the assessments were conducted, e.g., in a prerequisite course.
How often to assess. Programs need to sample outcomes from every student cohort to have an effective continuous improvement process. It is not required to assess all outcomes in every course nor all outcomes every year. Some programs do choose this approach, claiming it allows for quicker identification of, and response to, problematic items.
For four-year programs, some common assessment cycles for the 6-year cycle are shown in Table 1. Some programs assess all SOs every year. Other programs assess roughly half of the SOs each year. Finally, some programs assess roughly half of the SOs each year and additionally assess any SOs that were not attained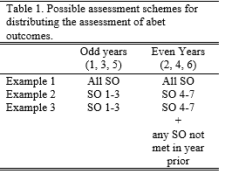 to acceptable levels in the previous assessment cycle. It is not necessary for the evaluation cycle to be the same as the assessment cycle, yet it is vital to assess results of any improvement actions taken. Some programs, particularly programs with small enrollments, may need to assess SOs every year and only evaluate every two years when enough data to provide authentic evidence have been gathered. Programs have the flexibility to determine their own processes.
to acceptable levels in the previous assessment cycle. It is not necessary for the evaluation cycle to be the same as the assessment cycle, yet it is vital to assess results of any improvement actions taken. Some programs, particularly programs with small enrollments, may need to assess SOs every year and only evaluate every two years when enough data to provide authentic evidence have been gathered. Programs have the flexibility to determine their own processes.
While a program may choose their cycle, there are some basic heuristics to follow. For four-year programs, assessing every outcome every year is not required; however, assessing only once every six years is clearly insufficient and not continuous. Likewise, for two-year programs, assessment may need to be conducted more frequently to ensure that all cohorts are assessed.
How many data are enough? ABET does not prescribe the amount of data to collect. Aside from the criterion requirement that all outcomes must be assessed, the number of data and data sources should be those which are sufficient (providing a lower bound) and sustainable (providing an upper bound) for making informed judgments about program improvement needs. The program is allowed by ABET to have the flexibility to determine how to sustainably collect the data considered necessary for making informed, evidence-based decisions. It is acceptable for a program to promote sustainable assessment practices through such means as data sampling within cohorts, data collection via learning management systems or other web-based tools, and cyclically working with only a subset of outcomes [4]. When sampling within cohorts, the samples should be chosen to be representative of the students in the program, and the student enrollment should be large enough to justify sampling [18]. Thus, sampling methods or procedures need to be clearly described and documented.
Acceptable data thresholds. Once performance indicators have been generated, the indicators need to be measured. One method that programs may implement is to develop a scale to benchmark performance using assignment scores. Programs often use rubrics with performance indicators to score student attainment. In this scenario, the rubric specifically describes a gradation of levels of attainment for each performance indicator. A given level and above will be deemed as acceptable or satisfactory performance, and the threshold will set the expectation of the percentage of students who are at the satisfactory level or above.
One approach for demonstrating successful attainment of an indicator is to set a minimum score for a given percentage of the class such as having at least 70% of the cohort achieve scores of 70% or higher on an assignment or exam that is focused on a single outcome. Unfortunately, some programs select artificially low performance thresholds or benchmarks that ensure that all student cohorts demonstrate sufficient attainment of all outcomes; in other cases, some programs select just those assessments where the standard is easily attained. In both cases, the data being collected may not be meaningful in that they provide no input to guide improvement actions. These are instances where a program evaluator can properly cite a shortcoming in that the input cannot be systematically utilized for program improvement as required by Criterion 4. Programs need to make sure that what is being measured is meaningful and is not simply a mechanistic way to appear to satisfy the criterion.
Non-numeric degree of attainment. Nothing in the criterion or definitions requires assessment results to be numeric, though many rely solely on quantitative measures [19]. For example, a rubric that measures the level of attainment with descriptors ranging from “needs improvement” to “exceeds expectations” can be an appropriate assessment measure. If this approach is taken, careful attention should be given to faculty training to pilot and generate inter-rater reliability. Non-numerical assessment data is also ideal for formative assessment where grading may not be needed or feasible. For instance, a non-numeric rubric can be used to observe students during a lab or simulation activity to capture affective or behavioral aspects of the experience. Additionally, non-numeric assessment may be short response data collected from surveys, faculty teaching evaluations, town halls, etc. that express program outcome related information that can be used in the continuous improvement process.
Team-based assessments. Team assessments can be an effective piece of an assessment process. It is common to see reports for comprehensive projects, integrating experiences, or capstone designs used for assessing both design- and communication-based outcomes. In such cases, it is not necessary for every student to write a separate design report, but it is good practice to also identify a complementary assessment of individual student writing skills as well, such as having team members take turns writing up progress reports. The program should have a means for determining how each student participated in the work leading to the team result; such methods might include peer evaluation or work logs with methods for charting each team member’s role [20].
EVALUATION
Gathering assessment data is just the first step of a continuous improvement process (see Fig. 1). Assessment data are useless without analysis and evaluation of results. Criterion 4 states that a “program must regularly use appropriate, documented processes for … evaluating the extent to which the student outcomes are being attained. As stated earlier, assessment and evaluation are different components of the continuous improvement process. Evaluation is the process step that converts data to information that can be used for meaningful improvement actions. While the authors have observed fewer issues here than in assessment practices, some common misconceptions do exist.
Averaging may be ineffective and undesirable. Averaging assessment results can hide diagnostic results of strengths and weaknesses in student learning, since evidence of low performance by one group can be masked by the high performance of another group. Accordingly, assessment results should not be averaged to give a single overall “score” for the attainment of an outcome; this applies both to averaging results from multiple performance indicators within a single outcome, and to averaging results from an outcome assessed at different class levels (formative vs. summative, 2nd-year students vs. 4th-year students).
When an evaluation result is not a number. Neither the criterion nor the definitions require evaluation results to be numeric. A qualitative process can be just as effective as a quantitative process if it leads to judgments about the need for program improvements and where in the curriculum they should be applied. When both quantitative and qualitative assessment data are brought together, there is not a need to merge them or combine numerically. Instead, data can be triangulated, cross referenced through multiple sources, to look for consistency or lack thereof among assessment data leading to evaluation decisions.
CONTINUOUS IMPROVEMENT ACTIONS
Continuous improvement, in a sense, is the “outcome” of the assessment and evaluation processes that the program has conducted. Criterion 4 states that the “results of these evaluations must be systematically utilized as input for the program’s continuous improvement actions” (ABET Criteria 2021-2022). Famously referred to as “closing the loop,” it is the continuous improvement actions, driven by assessment evidence, that improve our student learning outcomes. It is the lack of both closing the loop and the follow-up on the effect of improvement action that has often led to shortcomings identified in accreditation visits.
The purpose of criterion 4. The purpose of Criterion 4 is to promote evidence-based program improvements. Criterion 4 requires the results of the program’s evaluation process, which in turn is based on the program’s assessment processes, be systematically utilized by the faculty as input for the program’s continuous improvement actions. Accordingly, programs need to show the connection as to how their evaluation results inform the decisions made regarding program improvements. Programs should identify the following important features of their processes:
Are the evaluation inputs being used? Programs must consider opportunities to effect improvements based on a set of inputs that include the results of the evaluation of assessment data. If the inputs to the continuous improvement process indicate a need for improvement, justification for not acting should be appropriately documented. Possible reasons for not taking immediate action could include identified anomalies, prioritizing other areas for focus, budgetary and resource constraints, or natural disasters and pandemics.
Can other inputs be used? Criterion 4 explicitly allows additional information to be used as inputs into a program’s continuous improvement process. However, the only inputs required by the criterion are results of the evaluation process; programs should not be penalized if they limit their continuous improvement process to just the required inputs. Other inputs might include faculty suggestions, recommendations from advisory boards, curriculum improvements, and changes to the continuous improvement process itself.
DISCUSSION
We acknowledge that this paper is not exhaustive in its coverage of all possible considerations involved in developing and implementing an effective, sustainable continuous improvement process. While these best practices are well supported by engineering education literature, they were formed from stories and experiences of commissioners. This article presents “best practices”; however, no official “ABET Assessment Model” or “ABET Evaluation Model” exists or is implied. As mentioned previously, ABET provides training and resources that are publicly available for programs, however, they stop short of a level of detail needed to implement and understand the meaning behind the criteria. We are confident that the ideas and suggestions presented here will help guide programs and accreditation program evaluators in their contributions to improving the quality of our educational programs and our student learning.





